Q&A : よくご質問いただく項目と回答
テキストマイニング分析結果の利用について
- テレビ番組や新聞・雑誌等の記事内で、分析した結果を掲載することはできますか?
- テキストマイニング結果を、論文や学会発表、レポートに掲載していいですか?
- 入力したデータの内容が勝手に公開されることはありますか?
- 入力したデータの内容が、AIの学習等に利用されることはありますか?
データに関する質問
- 「共起」ってどんな意味ですか?
- 「スコア」について詳しく教えてください。
- 「2次元マップ」は何を意味していますか?内部的には、どんな処理をしていますか?
- 2次元マップでの、X・Y軸(縦軸・横軸)の数字はそれぞれ何を意味しているんですか?
- 2次元マップ中の単語の色は、何を意味しているんですか?
- 「階層的クラスタリング」とはなんですか?どのように読み取ればよいのですか?
- 階層的クラスタリングの樹形図の色はどんな意味があるのですか?
- 階層的クラスタリングの下にある横軸の数字は何を意味しているんですか?
- 「係り受け解析」とはなんですか?
- データ数・総文数・総単語数ってなんですか?
- 単語の出現傾向の「ラベル間出現率」の数値について詳しく教えてください。
困った時は?
テキストマイニング分析結果の利用について
テレビ番組や新聞・雑誌等の記事内で、分析した結果を掲載することはできますか?
テレビ番組、新聞、雑誌、Webサイトの媒体、YouTube動画にて、当AIテキストマイニングツールの分析結果画面を掲載なさりたい場合、
(1)出典としてツール名の明記 、 (2)掲載媒体・概要のご報告 の2点をしていただければ、無料にてご利用いただけます。
(1) 出典の明記
記事・番組でのご掲載時のクレジット表記は、以下のような形でお願いします。
【クレジット表記例】
※ユーザーローカルAIテキストマイニングによる分析( https://textmining.userlocal.jp/ )
または、
※ユーザーローカルAIテキストマイニングツールで調査 https://textmining.userlocal.jp/
ただし新聞記事・テレビ番組でURLの記載が難しい場合には、URL部分の記述は不要です。
(2) 掲載媒体・概要のご報告
テキストマイニング結果利用報告フォームからご報告をお願いします。※メールによる返信は行っておりません。
テキストマイニング結果を、論文や学会発表、レポートに掲載していいですか?
はい。テキストマイニング結果は、許諾なく論文などで無料で使用いただけます。これまでも多くの学生・研究者の方にご利用いただいております。ご利用時は、論文中、脚注や参考文献等に、弊社ツール名とURLを記載してください。
【記述例】
※ユーザーローカル テキストマイニングツール( https://textmining.userlocal.jp/ )による分析
論文をWebで公開なさる場合、そのURLを利用報告フォームからご報告いただけますと幸いです。今後のツール機能強化の参考とさせていただきます。
入力したデータの内容が勝手に公開されることはありますか?
テキストマイニングツールでご入力いただいた情報は、お試しになったご本人様が結果URLを外部に公開しないかぎり勝手に公開されることはございません。ご安心いただければと思います。
入力したデータの内容が、AIの学習等に利用されることはありますか?
入力いただいた情報は、生成AIなどのAI学習に利用されることはありませんのでご安心ください。
データに関する質問
「共起」ってどんな意味ですか?
共起とは、一文(改行や「。」などで区切られた各文)の中に、単語のセットが同時に出現するという意味です。共起回数は、一緒に出現した回数を指します。たとえば、
「あのメーカーが作った自転車は、とても速いらしい」
「速いスピードで自転車が駆け抜けていった」
という2文をテキストマイニングした場合、「自転車(名詞)」と「速い(形容詞)」という単語がセットで出現する(=共起している)回数は、それぞれ2回です。
・結果サンプルURL
https://textmining.userlocal.jp/results/MSiSUkStLtT6BNvzKZ18kW629tirxjuy#cooccurrence
一緒に出てくる単語を線で結んだものを「共起ネットワーク」と呼んでいます。
「スコア」について詳しく教えてください。
スコアは、その単語の「重要度」を表す値です。以下で、スコアがなぜ必要なのかと、その算出方法についてご紹介します。
一般的な文書では、単語の出現回数だけでいえば「今日」や「思う」「ある」などといった、”ごく一般的な単語”が何度も出現してしまいます。ただ、このような単語は、どういった文書にも出現する単語であるため、たとえ出現回数が多いとしても、意味が薄い、あまり重要ではない単語といえます。単純に回数だけをランキング化しても、一般的な語が混じってしまいその文章の特徴をつかむことができません。
この問題を解決するため、テキストマイニングでは、「一般的な文書でよく出る単語は、重要ではないため、重み付けを軽くする」、いっぽう「一般的な文書ではあまり出現しないけれど、調査対象の文書だけによく出現する単語は重視する」仕組みを取り入れています。
こういった特徴語を抽出するためのロジックとして、一般的にTF-IDF法という統計処理をします。
・参考URL
https://ja.wikipedia.org/wiki/Tf-idf
この手法によって、出現回数だけでなく、重要度を加味した値が「スコア」です。スコアが高い単語は、そのテキストを特徴づける単語であるといえます。
「2次元マップ」は何を意味していますか?内部的には、どんな処理をしていますか?
2次元マップは、文章中に単語の出現傾向を全体的に俯瞰するためのもので、「近くにある単語同士は同じ場所で出てくる傾向が強い」ということを意味しています(単語の出現傾向が似た単語ほど近く、似ていない単語ほど遠く配置)。
また、2次元座標系における位置の決定にはt-SNEという手法を用いています。
2次元マップでの、X・Y軸(縦軸・横軸)の数字はそれぞれ何を意味しているんですか?
2次元マップは単語間の相対的な距離を表しているだけですので、グラフ中のXY軸自体にはまったく意味がありません。近くの単語同士は出現傾向が似ていて、遠くの単語同士は出現傾向が近くない、ということだけを表しています。
2次元マップ中の単語の色は、何を意味しているんですか?
距離が近い単語を見やすくグルーピングするために色分けしています。同じ色の単語は近いグループに属しているといえます。
「階層的クラスタリング」とはなんですか?どのように読み取ればよいのですか?
出現傾向が似た単語を、似ているものから順にクラスタ(=グループ)としてまとめていくプロセスを示したものが、階層的クラスタリングです。生物の進化などで使われる樹形図と同様、似たものは近く(左側)で枝分かれし、似ていないものは遠く(右側)で枝分かれしています。これにより、出現傾向が似た単語のまとまりを、階層的に読み取ることができます。
クラスタをまとめるときの各単語・クラスタ間の近さ(出現傾向の類似度)は、クラスタをまとめる縦線の位置が左にあるほど近く、右にあるほど遠くなっており、線の結合通りに順番にまとめられます。たとえば、クラスタをまとめる位置がグラフの右側にある場合、出現傾向が比較的似ていないため、別々のクラスタとして見る方がよいと考えられます。
階層的クラスタリングの樹形図の色はどんな意味があるのですか?
クラスタをまとめるときに、クラスタ内の単語出現傾向が似ている場合は同じ色で、あまり似ていない場合は色を変えています。
階層的クラスタリングの下にある横軸の数字は何を意味しているんですか?
横軸の数字は、まとめられるクラスタ間の単語出現傾向の類似度を示しています。クラスタをまとめる縦線の位置と横軸が対応しています。
この数値自体は相対的なので、この数値が高いところ(右側)でまとめたクラスタより、低いところ(左側)でまとめたクラスタのほうが、クラスタに含まれる単語の出現傾向が似ていると言えます。
「係り受け解析」とはなんですか?
係り受け解析は、語句の「修飾 - 被修飾」関係を見つけるための解析方法です。
例えば、「このスマホの値段はそれほど高くない」という文の場合、各文節は以下のような「修飾 - 被修飾」関係になります。
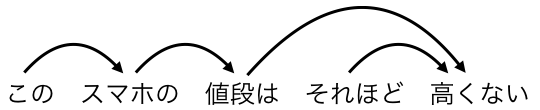
ここでは、矢印の開始地点の文節が、矢印の終了地点の文節を修飾しています。
係り受け解析では、この「修飾 - 被修飾」関係にあるそれぞれの文節から単語を抽出し、その単語ペアを集計します。
先程の例の場合だと、
「スマホの」と「値段は」という文節のペアから、【 スマホ(名詞) 】-【 値段(名詞) 】、
「値段は」と「高くない」という文節のペアから、【 値段(名詞) 】-【 高い(形容詞)+ ない(否定表現) 】
のような係り受けペアが得られます。
上記の「高くない」のように文節内に形容詞(高い)と否定表現(ない)が含まれている場合は、形容詞だけでなく否定表現も一緒に集計しています。
データ数・総文数・総単語数ってなんですか?
データ数とは、テキストファイル内の各ラベルに属する本文の数になります。 総文数とは、各ラベルの本文を集約し、文数を数えたものになります。 総単語数とは、各ラベルの本文を単語分割した際の単語数になります。ここでの単語は、名詞、形容詞、動詞、感動詞以外にも副詞、助詞等も含まれます。
単語の出現傾向の「ラベル間出現率」の数値について詳しく教えてください。
「ラベル間出現率」は、各ラベルごとにその単語がどのくらい出現するかを、ラベル間で比較するための値です。 この値は、ラベルごとの単語の出現率を、さらにラベル間での割合にすることで求めます。 ラベル間出現率の計算は以下の通りです。
- 各ラベルで対象単語の出現率(頻度/総単語数)を求める。
- ラベル間で出現率の割合(出現率/対象単語の出現率の合計)を求める
実際に、以下の表を例にして単語「購入」のラベル間出現率を計算してみます。 まず、「総単語数」と「購入(頻度)」はそれぞれ結果画面の《解析データ数》と《クロス集計》から得られます。 次に「購入(出現率)」は各ラベルごとに【「購入(頻度)」/「総単語数」】を計算することで得られます。 最後に、各ラベルの「購入(ラベル間出現率)」は【「購入(出現率)」/「購入(出現率)の合計」】になります。
| 星1つ | 星2つ | 星3つ | 星4つ | 星5つ | |
|---|---|---|---|---|---|
| 総単語数 | 1780 | 1994 | 1912 | 2246 | 1433 |
| 購入(頻度) | 9 | 20 | 15 | 26 | 21 |
| 購入(出現率) | 0.0051 | 0.0100 | 0.0078 | 0.0116 | 0.0147 |
| 購入(ラベル間出現率) | 10.3 | 20.4 | 16.0 | 23.5 | 29.8 |
困った時は?
カスタム辞書が解析結果に反映されない。
(1) 文書作成時に辞書設定する
「詳細設定を開く」をクリックし、「辞書設定」を利用したいカスタム辞書に変更してください。
(2) 作成済み文書の辞書設定を変更する
「文書一覧」から、カスタム辞書を利用したい文書の「編集」をクリックしてください。「辞書設定」の項目を利用したいカスタム辞書に変更してから「適用して再解析」をクリックしてください。
音声入力で「このブラウザは対応していません。」と表示される。
音声認識機能は Google Chrome Ver.33 以上でご利用いただけます。お手数ですが、Google Chrome Ver.33以上のブラウザで再度ご利用ください。
音声入力で「マイクが使用できません。」と表示される。
お使いのGoogle Chromeのマイクの許可設定を変更する必要があります。次の手順に従って、マイクの許可設定を「許可」に変更してください。
- 音声入力ページに移動してください。
- 「音声認識を開始」をクリックしてください。
- 画面右上に表示されるカメラアイコンをクリックしてください
- 「マイクがブロックされています」と表示されたことを確認してから、「https://textmining.userlocal.jp/がマイクへのアクセスを必要としているときは確認画面を表示する」にチェックを入れます。
- 再度「音声認識を開始」をクリックしてください
Excelクロス集計で利用可能な表データの作り方を教えてください。
データ作成時には次の点にご注意ください。
-
表データ中に「ラベル」「本文」それぞれに使用可能な列を含む。
Excelクロス集計では、表データから「ラベル」または「本文」として利用する列を選択し、ラベルごとに本文を集約、これをテキストマイニングします。ラベルの列と本文の列は重複できません。
表データは、少なくとも1列の「ラベル」と1列の「本文」を含むようにしてください。 -
列中に含まれるデータの種類が多すぎると「ラベル」として使用できない場合がある。
データの種類が多すぎる列はラベルとして使用できません。
例えば、日時や小数点付きの数字などはデータの種類が増加しやすく、ラベルとして利用できなくなる場合があります。この場合は以下のように、時・分・秒を削除する、小数点以下を切り捨てるなどの操作を行い、データの種類を減らすことを推奨しています。「2026年08月04日 02時30分」 → 「2026年08月04日」 「2.3」 → 「2」